Distributed Computing Workshop
On 24th July I led a workshop on distributed computing with a focus on what is MPI (the Message Passing Interface) and what is involved in assessing the scaling performance of MPI code, along with working through some examples.
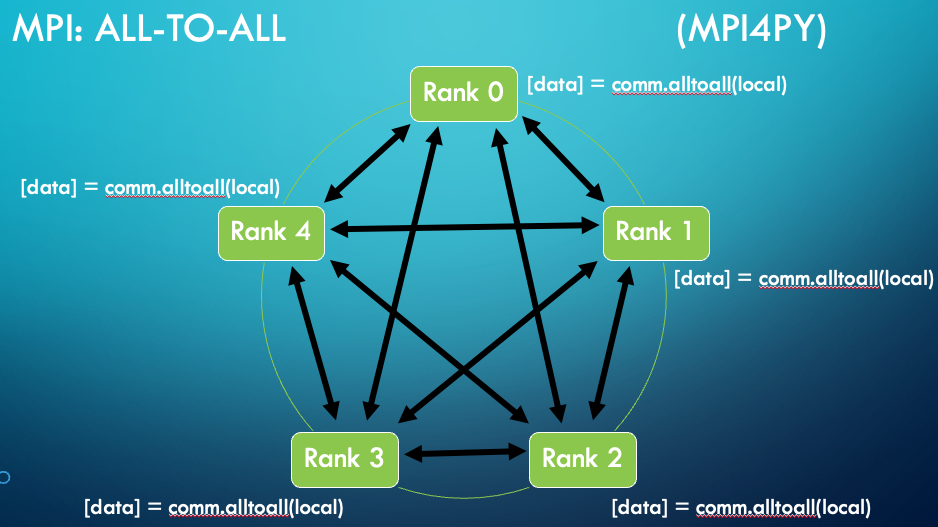
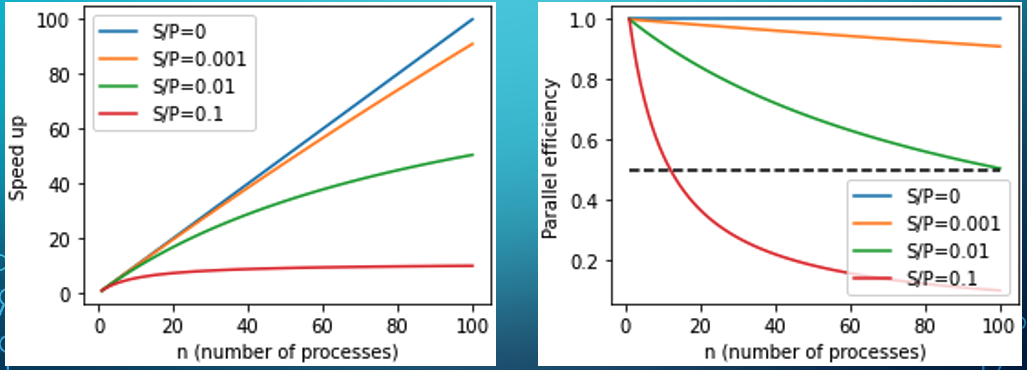
The workshop was attended by roughly 10 people from across the university at different career levels. The workshop started by walking through the basic concepts (communicators, ranks, etc.) and operations (send, receeve, all-to-all, etc.) defined by MPI. We then examined a simple performance model based on how much of your code can be parallelised. Lastly, we looked at several examples of how simple algorithms (such as counting primes, plotting the Mandelbrot set and solving a PDE) can be distributed using MPI and how the performance depends on how the work is distributed across processors.
This is a workshop that could readily be run again. If this sounds like something that yourself, your colleagues or your students might be interested in attending, please get in touch with myself or your local SNAP representative.
Workshop abstract:
This workshop will give participants an introduction to aspects of distributed computing. In the first half I’ll briefly discuss the key differences between distributed and shared memory parallelism, introduce the basic concepts and operations defined in the Message Passing Interface (MPI), describe simple models of how code ideally scales with the number of processes. In the second half, I’ll work through an example (or two) of writing and optimising parallel performance of a simple CPU bound problem (using mpi4py).
Back to top